UDP:用户数据报协议
UDP:用户数据报协议
引言
UDP是一个简单的面向数据报的运输层协议:进程的每个输出操作都正好产生一个 UDP 数据报,并组装成一份待发送的 I P数据报。这与面向流字符的协议不同,如TCP,应用程序产生的全体数据与真正发送的单个 IP 数据报可能没有什么联系。
UDP数据报封装成一份IP数据报的格式如图11-1所示。
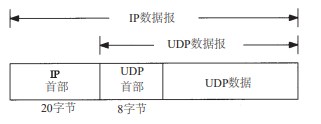
图11-1 UDP封装
RFC 768 [Postel 1980] 是UDP的正式规范。
UDP不提供可靠性:它把应用程序传给 IP层的数据发送出去,但是并不保证它们能到达目的地。由于缺乏可靠性,我们似乎觉得要避免使用 UDP而使用一种可靠协议如 TCP。
应用程序必须关心 IP 数据报的长度。如果它超过网络的 MTU,那么就要对 IP 数据报进行分片。如果需要,源端到目的端之间的每个网络都要进行分片,并不只是发送端主机连接第一个网络才这样做(我们在 2.9节中已定义了路径MTU的概念)。在11.5节中,我们将讨论 IP 分片机制。
UDP首部
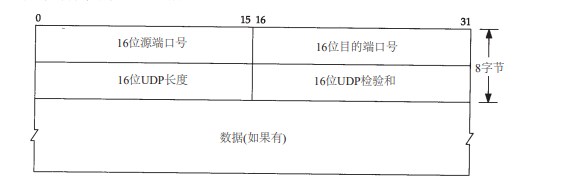
UDP首部的各字段如图11-2所示。
端口号表示发送进程和接收进程。由于 IP层已经把IP数据报分配给TCP或UDP(根据IP首部中协议字段值),因此TCP端口号由TCP来查看,而UDP端口号由UDP来查看。TCP端口号与UDP端口号是相互独立的。
尽管相互独立,如果TCP和UDP同时提供某种知名服务,两个协议通常选择相同的端口号。这纯粹是为了使用方便,而不是协议本身的要求。
UDP长度字段指的是UDP首部和UDP数据的字节长度。该字段的最小值为 8字节(发送一份0字节的 UDP数据报是OK)。这个 UDP长度是有冗余的。 IP数据报长度指的是数据报全长,因此UDP数据报长度是全长减去 IP首部的长度。
UDP检验和
UDP检验和覆盖UDP首部和UDP数据。回想IP首部的检验和,它只覆盖 IP的首部—并不覆盖IP数据报中的任何数据。
UDP和TCP在首部中都有覆盖它们首部和数据的检验和。 UDP的检验和是可选的,而TCP的检验和是必需的。
尽管UDP检验和的基本计算方法与我们在 3.2节中描述的 I P首部检验和计算方法相类似(16 bit字的二进制反码和),但是它们之间存在不同的地方。首先, UDP数据报的长度可以为奇数字节,但是检验和算法是把若干个 16 bit字相加。解决方法是必要时在最后增加填充字节0,这只是为了检验和的计算(也就是说,可能增加的填充字节不被传送)。其次,UDP数据报和TCP段都包含一个 12字节长的伪首部,它是为了计算检验和而设置的。伪首部包含 IP首部一些字段。其目的是让 UDP两次检查数据是否已经正确到达目的地(例如, I P没有接受地址不是本主机的数据报,以及 I P没有把应传给另一高层的数据报传给UDP)。UDP数据报中的伪首部格式如图 11-3所示。
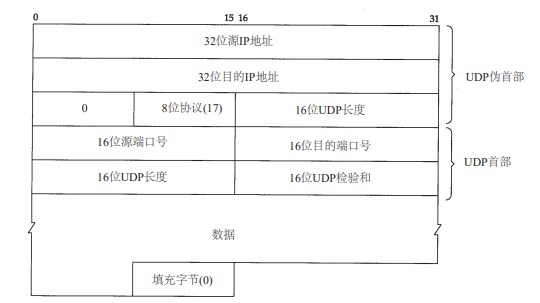
图11-3 UDP检验和计算过程中使用的各个字段
在该图中,我们特地举了一个奇数长度的数据报例子,因而在计算检验和时需要加上填充字节。注意,UDP数据报的长度在检验和计算过程中出现两次。
如果检验和的计算结果为 0,则存入的值为全 1(65535),这在二进制反码计算中是等效的。如果传送的检验和为0,说明发送端没有计算检验和。
如果发送端没有计算检验和而接收端检测到检验和有差错,那么 UDP数据报就要被悄悄地丢弃。不产生任何差错报文(当 IP层检测到IP首部检验和有差错时也这样做)。UDP检验和是一个端到端的检验和。它由发送端计算,然后由接收端验证。其目的是为了发现UDP首部和数据在发送端到接收端之间发生的任何改动。尽管UDP检验和是可选的,但是它们应该总是在用。在 80年代,一些计算机产商在默认条件下关闭UDP检验和的功能,以提高使用 UDP协议的NFS(Network File System)的速度。在单个局域网中这可能是可以接受的,但是在数据报通过路由器时,通过对链路层数据帧进行循环冗余检验(如以太网或令牌环数据帧)可以检测到大多数的差错,导致传输失败。不管相信与否,路由器中也存在软件和硬件差错,以致于修改数据报中的数据。如果关闭端到端的UDP检验和功能,那么这些差错在 UDP数据报中就不能被检测出来。另外,一些数据链路层协议(如SLI P)没有任何形式的数据链路检验和。
Host Requirements RFC声明,UDP检验和选项在默认条件下是打开的。它还声明,如果发送端已经计算了检验和,那么接收端必须检验接收到的检验和(如接收到检验和不为0)。但是,许多系统没有遵守这一点,只是在出口检验和选项被打开时才验证接收到的检验和。
tcpdump输出
很难知道某个特定系统是否打开了 UDP 检验和选项。应用程序通常不可能得到接收到的UDP首部中的检验和。为了得到这一点,作者在 tcpdump程序中增加了一个选项,以打印出接收到的UDP检验和。如果打印出的值为 0,说明发送端没有计算检验和。
IP分片
正如我们在2.8节描述的那样,物理网络层一般要限制每次发送数据帧的最大长度。任何时候IP层接收到一份要发送的 IP数据报时,它要判断向本地哪个接口发送数据(选路),并查询该接口获得其MTU。IP把MTU与数据报长度进行比较,如果需要则进行分片。分片可以发生在原始发送端主机上,也可以发生在中间路由器上。
把一份IP数据报分片以后,只有到达目的地才进行重新组装(这里的重新组装与其他网络协议不同,它们要求在下一站就进行进行重新组装,而不是在最终的目的地)。重新组装由目的端的 IP层来完成,其目的是使分片和重新组装过程对运输层( TCP和UDP)是透明的,除了某些可能的越级操作外。已经分片过的数据报有可能会再次进行分片(可能不止一次)。IP首部中包含的数据为分片和重新组装提供了足够的信息。
尽管IP分片过程看起来是透明的,但有一点让人不想使用它:即使只丢失一片数据也要重传整个数据报。为什么会发生这种情况呢?因为 IP层本身没有超时重传的机制——由更高层来负责超时和重传(TCP有超时和重传机制,但UDP没有。一些UDP应用程序本身也执行超时和重传)。当来自TCP报文段的某一片丢失后,TCP在超时后会重发整个TCP报文段,该报文段对应于一份IP数据报。没有办法只重传数据报中的一个数据报片。事实上,如果对数据报分片的是中间路由器,而不是起始端系统,那么起始端系统就无法知道数据报是如何被分片的。就这个原因,经常要避免分片。
ICMP不可达差错(需要分片)
发生ICMP不可达差错的另一种情况是,当路由器收到一份需要分片的数据报,而在 IP首部又设置了不分片(DF)的标志比特。如果某个程序需要判断到达目的端的路途中最小 MTU是多少—称作路径MTU发现机制(2.9节),那么这个差错就可以被该程序使用。这种情况下的ICMP不可达差错报文格式如图 11-9所示。这里的格式与图 6-10不同,因为在第2个32 bit字中,16~31 bit可以提供下一站的MTU,而不再是0。

图11-9 需要分片但又设置不分片标志比特时的ICMP不可达差错报文格式
如果路由器没有提供这种新的 ICMP差错报文格式,那么下一站的 MTU就设为0。新版的路由器需求RFC声明,在发生这种ICMP不可达差错时,路由器必须生成这种新格式的报文。
用Traceroute确定路径MTU
尽管大多数的系统不支持路径 MTU发现功能,但可以很容易地修改 traceroute程序(第8章),用它来确定路径 MTU。要做的是发送分组,并设置“不分片”标志比特。发送的第一个分组的长度正好与出口 MTU相等,每次收到ICMP “不能分片”差错时(在上一节讨论的)就减小分组的长度。如果路由器发送的 ICMP差错报文是新格式,包含出口的 MTU,那么就用该MTU值来发送,否则就用下一个最小的 MTU值来发送。正如 RFC 1191 [Mogul and Deering 1990]声明的那样,MTU值的个数是有限的,因此在我们的程序中有一些由近似值构成的表,取下一个最小MTU值来发送。
最大UDP数据报长度
理论上,IP数据报的最大长度是65535字节,这是由IP首部16比特总长度字段所限制的。去除 20字节的IP首部和8个字节的UDP首部,UDP数据报中用户数据的最长长度为65507字节。但是,大多数实现所提供的长度比这个最大值小。我们将遇到两个限制因素。第一,应用程序可能会受到其程序接口的限制。 socket API提供了一个可供应用程序调用的函数,以设置接收和发送缓存的长度。对于 UDP socket,这个长度与应用程序可以读写的最大 U D P数据报的长度直接相关。现在的大部分系统都默认提供了可读写大于 8192字节的UDP数据报(使用这个默认值是因为 8192是NFS读写用户数据数的默认值)。
第二个限制来自于TCP/IP的内核实现。可能存在一些实现特性(或差错),使I P数据报长度小于65535字节